
 please click here to earn
please click here to earn
🥀MACHINE LEARNING🥀
❁ Neural Network ❁
If network has sj units in layer j and sj+1 units in layer j+1, then Θ(j) If network has sj units in layer j and sj+1 units in layer j+1,

Questions & Answers
b) self inhibitory
c) self excitatory or self inhibitory
d) none of the mentioned
❁ Neural Network ❁
Neural network or the neural nets described by McCullough and Pitts in 1944 had thresholds and weights, but they were not arranged into layers, and the researchers didn’t specify any training mechanism. What McCullough and Pitts showed was that a neural net could, in principle, compute any function that a digital computer able to do. The result was more neuroscience than computer science: The point was to suggest that the human brain could be thought of as a computing machine
Neural networks continue to be a important tool for neuroscientific research. For instance, particular network layouts or rules for adjusting weights and thresholds have reproduced observed features of human neuroanatomy and cognition, an indication that they capture something about how the brain stimulate the information.
Representation
Generally, a simplistic representation looks like:
We can have intermediate layers of nodes between the input and output layers called the "hidden layers."
In this example, we label these intermediate or "hidden" layer nodes a20⋯a2n and call them "activation units."
If we had one hidden layer, it would look like:
The values for each of the "activation" nodes is obtained as follows:
This is saying that we compute our activation nodes by using a 3×4 matrix of parameters. We apply each row of the parameters to our inputs to obtain the value for one activation node. Our hypothesis output is the logistic function applied to the sum of the values of our activation nodes, which have been multiplied by yet another parameter matrix Θ(2) containing the weights for our second layer of nodes.
Each layer gets its own matrix of weights, Θ(j) .
The dimensions of these matrices of weights is determined as follows:
then Θ(j) will be of dimension sj+1×(sj+1).Θ
The +1 comes from the addition in Θ(j) of the "bias nodes," and Θ(j)0 . In other words the output nodes will not include the bias nodes while the inputs will. The following image summarizes our model representation:

Example: If layer 1 has 2 input nodes and layer 2 has 4 activation nodes. Dimension of Θ(1) is going to be 4×3 where and , so .
Cost Function
Let's first define a few variables that we will need to use:
- L = total number of layers in the network
- = number of units (not counting bias unit) in layer l
- K = number of output units/classes
Recall that in neural networks, we may have many output nodes. We denote hΘ(x)k as being a hypothesis that results in the output. Our cost function for neural networks is going to be a generalization of the one we used for logistic regression. Recall that the cost function for regularized logistic regression was:
For neural networks, it is going to be slightly more complicated:
We have added a few nested summations to account for our multiple output nodes. In the first part of the equation, before the square brackets, we have an additional nested summation that loops through the number of output nodes.
In the regularization part, after the square brackets, we must account for multiple theta matrices. The number of columns in our current theta matrix is equal to the number of nodes in our current layer (including the bias unit). The number of rows in our current theta matrix is equal to the number of nodes in the next layer (excluding the bias unit). As before with logistic regression, we square every term.
Note:
- the double sum simply adds up the logistic regression costs calculated for each cell in the output layer
- the triple sum simply adds up the squares of all the individual Θs in the entire network.
- the i in the triple sum does not refer to training example i
Q1. Batch Normalization is helpful because
A. It normalizes (changes) all the input before sending it to the next layer
B. It returns back the normalized mean and standard deviation of weights
C. It is a very efficient backpropagation technique
D. None of these
Solution: (A)
Q2. Instead of trying to achieve absolute zero error, we set a metric called bayes error which is the error we hope to achieve. What could be the reason for using bayes error?
A. Input variables may not contain complete information about the output variable
B. System (that creates input-output mapping) may be stochastic
C. Limited training data
D. All the above
Solution: (D)
In reality achieving accurate prediction is a myth. So we should hope to achieve an “achievable result”.
Q3. The number of neurons in the output layer should match the number of classes (Where the number of classes is greater than 2) in a supervised learning task. True or False?
A. True
B. False
Solution: (B)
It depends on output encoding. If it is one-hot encoding, then its true. But you can have two outputs for four classes, and take the binary values as four classes(00,01,10,11).
Q4. In a neural network, which of the following techniques is used to deal with overfitting?
A. Dropout
B. Regularization
C. Batch Normalization
D. All of these
Solution: (D)
All of the techniques can be used to deal with overfitting.
Q5. Y = ax^2 + bx + c (polynomial equation of degree 2)
Can this equation be represented by a neural network of single hidden layer with linear threshold?
A. True
B. False
Solution: (B)
The answer is false because having a linear threshold restricts your neural network and in simple terms, makes it a consequential linear transformation function.
Q6. What is a dead unit in a neural network?
A. A unit which doesn’t update during training by any of its neighbour
B. A unit which does not respond completely to any of the training patterns
C. The unit which produces the biggest sum-squared error
D. None of these
Solution: (A)
Option A is correct.
Q7. Which of the following statement is the best description of early stopping?
A. Train the network until a local minimum in the error function is reached
B. Simulate the network on a test dataset after every epoch of training. Stop training when the generalization error starts to increase
C. Add a momentum term to the weight update in the Generalized Delta Rule, so that training converges more quickly
D. A faster version of backpropagation, such as the `Quickprop’ algorithm
Solution: (B)
Option B is correct.
Q8. What if we use a learning rate that’s too large?
A. Network will converge
B. Network will not converge
C. Can’t Say
Solution: B
Option B is correct because the error rate would become erratic and explode.
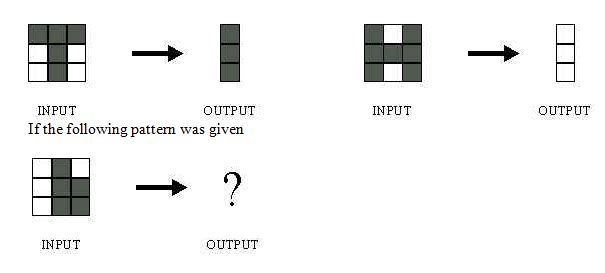
Q9. The network shown in Figure 1 is trained to recognize the characters H and T as shown below:
What would be the output of the network?



- Could be A or B depending on the weights of neural network
Solution: (D)
Q10. Suppose a convolutional neural network is trained on ImageNet dataset (Object recognition dataset). This trained model is then given a completely white image as an input.The output probabilities for this input would be equal for all classes. True or False?
A. True
B. False
Solution: (B)
There would be some neurons which are do not activate for white pixels as input. So the classes wont be equal.
Q11. When pooling layer is added in a convolutional neural network, translation in-variance is preserved. True or False?
A. True
B. False
Solution: (A)
Translation invariance is induced when you use pooling.
Q12. Which gradient technique is more advantageous when the data is too big to handle in RAM simultaneously?
A. Full Batch Gradient Descent
B. Stochastic Gradient Descent
Solution: (B)
Option B is correct.
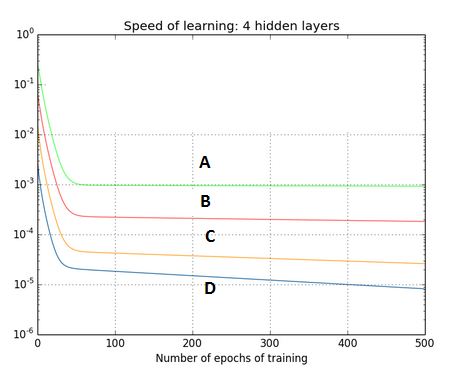
Q13. The graph represents gradient flow of a four-hidden layer neural network which is trained using sigmoid activation function per epoch of training. The neural network suffers with the vanishing gradient problem.
Which of the following statements is true?
A. Hidden layer 1 corresponds to D, Hidden layer 2 corresponds to C, Hidden layer 3 corresponds to B and Hidden layer 4 corresponds to A
B. Hidden layer 1 corresponds to A, Hidden layer 2 corresponds to B, Hidden layer 3 corresponds to C and Hidden layer 4 corresponds to D
Solution: (A)
This is a description of a vanishing gradient problem. As the backprop algorithm goes to starting layers, learning decreases.
Q14. For a classification task, instead of random weight initializations in a neural network, we set all the weights to zero. Which of the following statements is true?
A. There will not be any problem and the neural network will train properly
B. The neural network will train but all the neurons will end up recognizing the same thing
C. The neural network will not train as there is no net gradient change
D. None of these
Solution: (B)
Option B is correct.
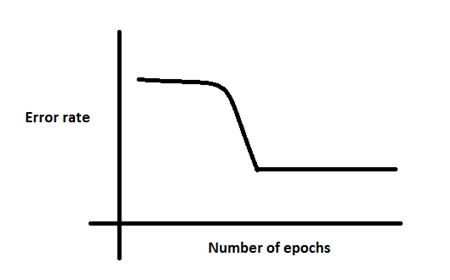
Q15. There is a plateau at the start. This is happening because the neural network gets stuck at local minima before going on to global minima.
To avoid this, which of the following strategy should work?
A. Increase the number of parameters, as the network would not get stuck at local minima
B. Decrease the learning rate by 10 times at the start and then use momentum
C. Jitter the learning rate, i.e. change the learning rate for a few epochs
D. None of these
Solution: (C)
Option C can be used to take a neural network out of local minima in which it is stuck.
Q16. For an image recognition problem (recognizing a cat in a photo), which architecture of neural network would be better suited to solve the problem?
A. Multi Layer Perceptron
B. Convolutional Neural Network
C. Recurrent Neural network
D. Perceptron
Solution: (B)
Convolutional Neural Network would be better suited for image related problems because of its inherent nature for taking into account changes in nearby locations of an image
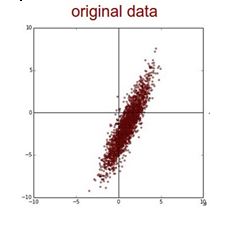
Q17. Suppose while training, you encounter this issue. The error suddenly increases after a couple of iterations.
You determine that there must a problem with the data. You plot the data and find the insight that, original data is somewhat skewed and that may be causing the problem.
What will you do to deal with this challenge?
A. Normalize
B. Apply PCA and then Normalize
C. Take Log Transform of the data
D. None of these
Solution: (B)
First you would remove the correlations of the data and then zero center it.
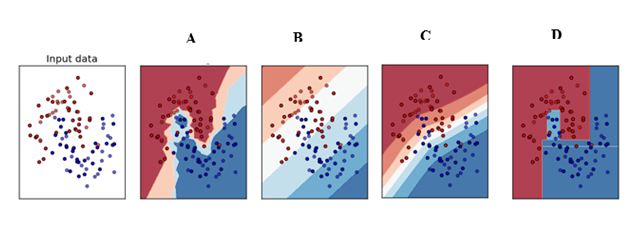
Q18. Which of the following is a decision boundary of Neural Network?
A) B
B) A
C) D
D) C
E) All of these
Solution: (E)
A neural network is said to be a universal function approximator, so it can theoretically represent any decision boundary.
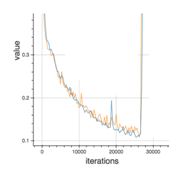
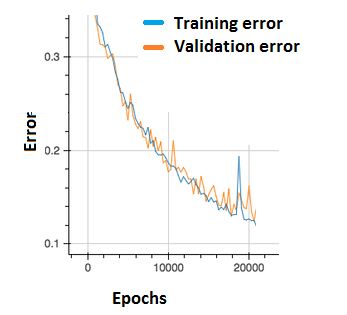
Q19. In the graph below, we observe that the error has many “ups and downs”
Should we be worried?
A. Yes, because this means there is a problem with the learning rate of neural network.
B. No, as long as there is a cumulative decrease in both training and validation error, we don’t need to worry.
Solution: (B)
Option B is correct. In order to decrease these “ups and downs” try to increase the batch size.
Q20. What are the factors to select the depth of neural network?
- Type of neural network (eg. MLP, CNN etc)
- Input data
- Computation power, i.e. Hardware capabilities and software capabilities
- Learning Rate
- The output function to map
A. 1, 2, 4, 5
B. 2, 3, 4, 5
C. 1, 3, 4, 5
D. All of these
Solution: (D)
All of the above factors are important to select the depth of neural network
Q21. Consider the scenario. The problem you are trying to solve has a small amount of data. Fortunately, you have a pre-trained neural network that was trained on a similar problem. Which of the following methodologies would you choose to make use of this pre-trained network?
A. Re-train the model for the new dataset
B. Assess on every layer how the model performs and only select a few of them
C. Fine tune the last couple of layers only
D. Freeze all the layers except the last, re-train the last layer
Solution: (D)
If the dataset is mostly similar, the best method would be to train only the last layer, as previous all layers work as feature extractors.
Q22. Increase in size of a convolutional kernel would necessarily increase the performance of a convolutional network.
A. True
B. False
Solution: (B)
Q23. Increasing kernel size would not necessarily increase performance. This depends heavily on the dataset.

Create a neural network with only one hidden layer (of any number of units) that implements (A ∨
¬B) ⊕ (¬C ∨ ¬D). Draw your network, and show all weights of each unit.
Figure 2: An example of neural network for problem 1.4
F SOLUTION: Note that XOR operation can be written in terms of AND and OR operations: p⊕q =
(p ∧ ¬q) ∨ (¬p ∧ q). Given this, we can rewrite the formula as (A ∧ C ∧ D) ∨ (¬B ∧ C ∧ D) ∨ (¬A ∧ B ∧
¬C) ∨ (¬A ∧ B ∧ ¬D). This formula can be represented by a neural network with one hidden layer and
four nodes in the hidden layer (one unit for each parenthesis). An example is shown in Figure 2.
Q24 Temporal Processing (a) With a supervised learning algorithm, we can specify target output values, but we may never
get close to those targets at the end of learning. Give two reasons why this might happen.
Answer: (i) data may be valid, and inconsistency results from a stochastic aspect of the task (or some aspect of the task is not modelled by the input data collected);
(ii) the data may contain errors - e.g. measurement errors or typographical errors
Q25 Describe the architecture and the computational task of the NetTalk neural network
. Answer: architecture: ... 203 input units (= 7*29) ... ! 80 hidden neurons ... ! one output neuron per English phoneme,

Q26.How are input layer units connected to second layer in competitive learning networks?
a) feedforward manner
b) feedback manner
c) feedforward and feedback
d) feedforward or feedback
Answer: (i) data may be valid, and inconsistency results from a stochastic aspect of the task (or some aspect of the task is not modelled by the input data collected);
(ii) the data may contain errors - e.g. measurement errors or typographical errors
Q25 Describe the architecture and the computational task of the NetTalk neural network
. Answer: architecture: ... 203 input units (= 7*29) ... ! 80 hidden neurons ... ! one output neuron per English phoneme,

Q26.How are input layer units connected to second layer in competitive learning networks?
a) feedforward manner
b) feedback manner
c) feedforward and feedback
d) feedforward or feedback
Answer: a
Explanation: The output of input layer is given to second layer with adaptive feedforward weights.
Explanation: The output of input layer is given to second layer with adaptive feedforward weights.
Q27 What is the nature of general feedback given in competitive neural networks?
a) self excitatoryb) self inhibitory
c) self excitatory or self inhibitory
d) none of the mentioned
Answer: a
Explanation: The output of each unit in second layer is fed back to itself in self – excitatory manner.
Explanation: The output of each unit in second layer is fed back to itself in self – excitatory manner.
What is a training set and how is it used to train neural networks?
Answer: Training set is a set of pairs of input patterns with corresponding
desired output patterns. Each pair represents how the network is supposed
to respond to a particular input. The network is trained to respond correctly
to each input pattern from the training set. Training algorithms that use
training sets are called supervised learning algorithms. We may think of
a supervised learning as learning with a teacher, and the training set as a
set of examples. During training the network, when presented with input
patterns, gives ‘wrong’ answers (not desired output). The error is used to
adjust the weights in the network so that next time the error was smaller.
This procedure is repeated using many examples (pairs of inputs and desired
outputs) from the training set until the error becomes sufficiently small
Q28.What is an epoch?
Answer: An epoch is when all of the data in the training set is presented
to the neural network once.
🙏🙏Please hit the 🔔Bell icon to get the notrification from Abhinav's Blog
Abhinav's Blog
🙏🙏Please hit the 🔔Bell icon to get the notrification from
Abhinav's Blog
No comments:
Post a Comment