
 please click here to earn
please click here to earn 🥀MACHINE LEARNING🥀
🌻 K - means Algorithm🌻
K-means algorithm is one of the easiest and popular unsupervised machine learning algorithms. In other words, the K-means algorithm identifies k number of centroids, and then allocates every data point to the nearest cluster, while keeping the centroids as small as possible.
🙂Due to allocating data points to the nearest cluster it also known as K-means clustering.
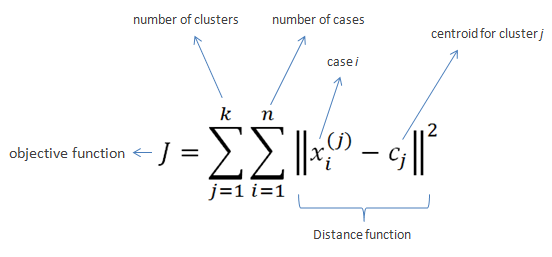



- K-means is used for cluster analysis on a large scale
- Much comfortable & Easy to understand
- Trains rapidly
- Disadvantages of K-Means:
- Euclidean distance is not ideal in many applications
- Performance is (generally) not competitive with the best clustering methods
- Small variations in the data can result in a completely different clusters (high variance)
- Clusters are taken to have a spherical shape and be same sized



Ealuating value of K:



The algorithm explained above finds clusters for the number k that we choose. So, how do we decide on that number?
To find the accurate k we need to measure the quality of the clusters. The most traditional and direct method is to start with a random k, create centroids, and run the algorithm as we explained above. A sum is given based on the distances between each point and its closest centroid. As an increase in clusters correlates with smaller groupings and distances, this sum will always decrease when k increases; as an extreme example, if we choose a k value that is equal to the number of data points that we have, the sum will be zero.
The goal with this process is to find the point at which increasing k will cause a very small decrease in the error sum, while decreasing k will sharply increase the error sum. This sweet spot is called the “elbow point.” In the image below, it is clear that the “elbow” point is at k-3.
Question & Answer
Q1. Movie Recommendation systems are an example of:
- Classification
- Clustering
- Reinforcement Learning
- Regression
Options:
B. A. 2 Only
C. 1 and 2
D. 1 and 3
E. 2 and 3
F. 1, 2 and 3
H. 1, 2, 3 and
Q2.Sentiment Analysis is an example of:
- Regression
- Classification
- Clustering
- Reinforcement Learning
Options:
A. 1 Only
B. 1 and 2
C. 1 and 3
D. 1, 2 and 3
E. 1, 2 and 4
F. 1, 2, 3 and 4
Q3. Can decision trees be used for performing clustering?
A. True
B. False
Solution: (A)
Q4.For two runs of K-Mean clustering is it expected to get same clustering results?
A. True
B. False
Solution: (B)
Q5.Is it possible that Assignment of observations to clusters does not change between successive iterations in K-Means
A. True
B. False
C. Can’t say
D. None of these
Solution: (A)
Q6. Which of the following can act as possible termination conditions in K-Means?
- For a fixed number of iterations.
- Assignment of observations to clusters does not change between iterations. Except for cases with a bad local minimum.
- Centroids do not change between successive iterations.
- Terminate when RSS falls below a threshold.
Options:
A. 1, 3 and 4
B. 1, 2 and 3
C. 1, 2 and 4
D. All of the above
Solution: (D)
All four conditions can be used as possible termination condition in K-Means clustering:
- This condition limits the runtime of the clustering algorithm, but in some cases the quality of the clustering will be poor because of an insufficient number of iterations.
- Except for cases with a bad local minimum, this produces a good clustering, but runtimes may be unacceptably long.
- This also ensures that the algorithm has converged at the minima.
- Terminate when RSS falls below a threshold. This criterion ensures that the clustering is of a desired quality after termination. Practically, it’s a good practice to combine it with a bound on the number of iterations to guarantee termination.
Q7. What should be the best choice of no. of clusters based on the following results:
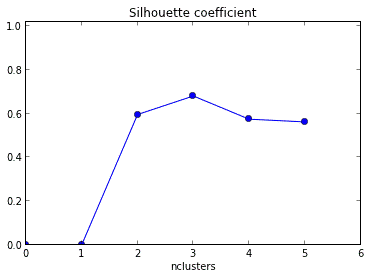
A. 1
B. 2
C. 3
D. 4
Solution: (C)
Q9. Which of the following clustering algorithms suffers from the problem of convergence at local optima?
- K- Means clustering algorithm
- Agglomerative clustering algorithm
- Expectation-Maximization clustering algorithm
- Diverse clustering algorithm
Options:
A. 1 only
B. 2 and 3
C. 2 and 4
D. 1 and 3
E. 1,2 and 4
F. All of the above
Solution: (D)
Out of the options given, only K-Means clustering algorithm and EM clustering algorithm has the drawback of converging at local minima.
Q10. Which of the following algorithm is most sensitive to outliers?
A. K-means clustering algorithm
B. K-medians clustering algorithm
C. K-modes clustering algorithm
D. K-medoids clustering algorithm
Solution: (A)
Out of all the options, K-Means clustering algorithm is most sensitive to outliers as it uses the mean of cluster data points to find the cluster center.
Q11. After performing K-Means Clustering analysis on a dataset, you observed the following dendrogram. Which of the following conclusion can be drawn from the dendrogram?
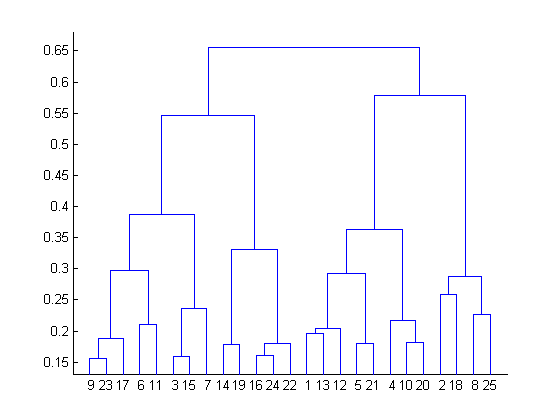
A. There were 28 data points in clustering analysis
B. The best no. of clusters for the analyzed data points is 4
C. The proximity function used is Average-link clustering
D. The above dendrogram interpretation is not possible for K-Means clustering analysis
Solution: (D)
Q. How can Clustering (Unsupervised Learning) be used to improve the accuracy of Linear Regression model (Supervised Learning):
- Creating different models for different cluster groups.
- Creating an input feature for cluster ids as an ordinal variable.
- Creating an input feature for cluster centroids as a continuous variable.
- Creating an input feature for cluster size as a continuous variable.
Options:
A. 1 only
B. 1 and 2
C. 1 and 4
D. 3 only
E. 2 and 4
F. All of the above
Solution: (F)
Q13. What could be the possible reason(s) for producing two different dendrograms using agglomerative clustering algorithm for the same dataset?
A. Proximity function used
B. of data points used
C. of variables used
D. B and c only
E. All of the above
Solution: (E)
Q14. In the figure below, if you draw a horizontal line on y-axis for y=2. What will be the number of clusters formed?
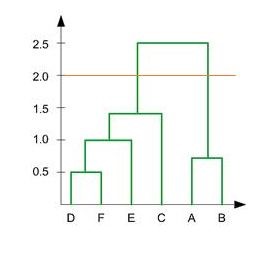
A. 1
B. 2
C. 3
D. 4
Solution: (B)
Which of the following is/are valid iterative strategy for treating missing values before clustering analysis?
A. Imputation with mean
B. Nearest Neighbor assignment
C. Imputation with Expectation Maximization algorithm
D. All of the above
Solution: (C)
All of the mentioned techniques are valid for treating missing values before clustering analysis but only imputation with EM algorithm is iterative in its functioning.
Q25. K-Mean algorithm has some limitations. One of the limitation it has is, it makes hard assignments(A point either completely belongs to a cluster or not belongs at all) of points to clusters.
Note: Soft assignment can be consider as the probability of being assigned to each cluster: say K = 3 and for some point xn, p1 = 0.7, p2 = 0.2, p3 = 0.1)
Which of the following algorithm(s) allows soft assignments?
- Gaussian mixture models
- Fuzzy K-means
Options:
A. 1 only
B. 2 only
C. 1 and 2
D. None of these
Solution: (C)
Q16. Assume, you want to cluster 7 observations into 3 clusters using K-Means clustering algorithm. After first iteration clusters, C1, C2, C3 has following observations:
C1: {(2,2), (4,4), (6,6)}
C2: {(0,4), (4,0)}
C3: {(5,5), (9,9)}
What will be the cluster centroids if you want to proceed for second iteration?
A. C1: (4,4), C2: (2,2), C3: (7,7)
B. C1: (6,6), C2: (4,4), C3: (9,9)
C. C1: (2,2), C2: (0,0), C3: (5,5)
D. None of these
Solution: (A)
Calculating centroid for data points in cluster C1 = ((2+4+6)/3, (2+4+6)/3) = (4, 4)
Calculating centroid for data points in cluster C2 = ((0+4)/2, (4+0)/2) = (2, 2)
Calculating centroid for data points in cluster C3 = ((5+9)/2, (5+9)/2) = (7, 7)
Hence, C1: (4,4), C2: (2,2), C3: (7,7)
Q17. Assume, you want to cluster 7 observations into 3 clusters using K-Means clustering algorithm. After first iteration clusters, C1, C2, C3 has following observations:
C1: {(2,2), (4,4), (6,6)}
C2: {(0,4), (4,0)}
C3: {(5,5), (9,9)}
What will be the Manhattan distance for observation (9, 9) from cluster centroid C1. In second iteration.
A. 10
B. 5*sqrt(2)
C. 13*sqrt(2)
D. None of these
Solution: (A)
Manhattan distance between centroid C1 i.e. (4, 4) and (9, 9) = (9-4) + (9-4) = 10
Q18. If two variables V1 and V2, are used for clustering. Which of the following are true for K means clustering with k =3?
- If V1 and V2 has a correlation of 1, the cluster centroids will be in a straight line
- If V1 and V2 has a correlation of 0, the cluster centroids will be in straight line
Options:
A. 1 only
B. 2 only
C. 1 and 2
D. None of the above
Solution: (A)
Q19. Feature scaling is an important step before applying K-Mean algorithm. What is reason behind this?
A. In distance calculation it will give the same weights for all features
B. You always get the same clusters. If you use or don’t use feature scaling
C. In Manhattan distance it is an important step but in Euclidian it is not
D. None of these
Solution; (A)
Q20. Which of the following method is used for finding optimal of cluster in K-Mean algorithm?
A. Elbow method
B. Manhattan method
C. Ecludian mehthod
D. All of the above
E. None of these
Solution: (A)
Q21. What is true about K-Mean Clustering?
- K-means is extremely sensitive to cluster center initializations
- Bad initialization can lead to Poor convergence speed
- Bad initialization can lead to bad overall clustering
Options:
A. 1 and 3
B. 1 and 2
C. 2 and 3
D. 1, 2 and 3
Solution: (D)
Q22. Which of the following can be applied to get good results for K-means algorithm corresponding to global minima?
- Try to run algorithm for different centroid initialization
- Adjust number of iterations
- Find out the optimal number of clusters
Options:
A. 2 and 3
B. 1 and 3
C. 1 and 2
D. All of above
Solution: (D)
Q23. What should be the best choice for number of clusters based on the following results:
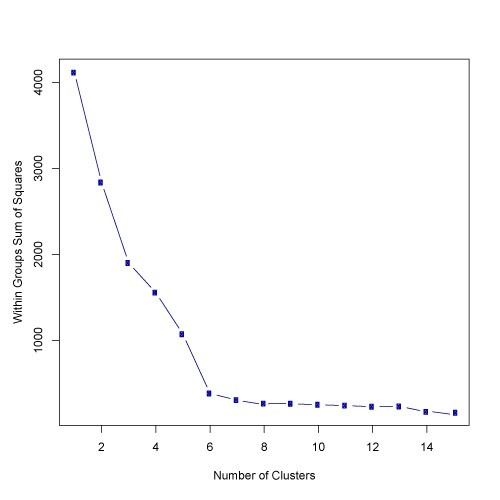
A. 5
B. 6
C. 14
D. Greater than 14
Solution: (B)
Based on the above results, the best choice of number of clusters using elbow method is 6.
Q24. What should be the best choice for number of clusters based on the following results:
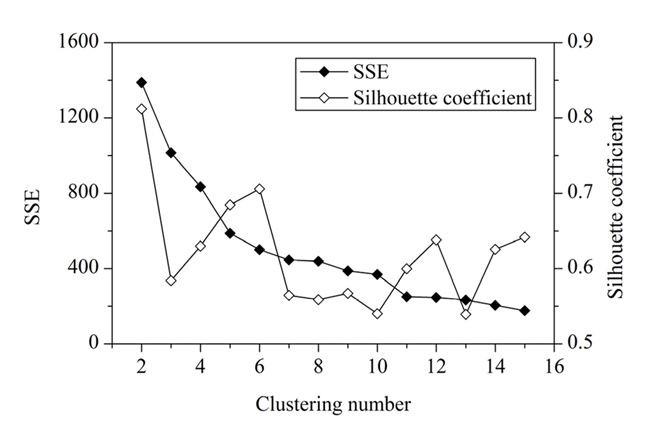
A. 2
B. 4
C. 6
D. 8
Solution: (C)
Q25. Which of the following sequences is correct for a K-Means algorithm using Forgy method of initialization?
- Specify the number of clusters
- Assign cluster centroids randomly
- Assign each data point to the nearest cluster centroid
- Re-assign each point to nearest cluster centroids
- Re-compute cluster centroids
Options:
A. 1, 2, 3, 5, 4
B. 1, 3, 2, 4, 5
C. 2, 1, 3, 4, 5
D. None of these
Solution: (A)
Q26. If you are using Multinomial mixture models with the expectation-maximization algorithm for clustering a set of data points into two clusters, which of the assumptions are important:
A. All the data points follow two Gaussian distribution
B. All the data points follow n Gaussian distribution (n >2)
C. All the data points follow two multinomial distribution
D. All the data points follow n multinomial distribution (n >2)
Solution: (C)
Q27.Like the probabilistic view, the ________ view allows us to associate a probability of membership with each classification.
A. exemplar
B. deductive
C. classical
D. inductive
Solution: (B)
Q28.This iDA component allows us to decide if we wish to process an entire dataset or to extract a representative subset of the data for mining.
a. preprocessor
b. heuristic agent
c. ESX
d. RuleMaker
ANS:b
Q29.Data used to build a data mining model.
a. validation data
b. training data
c. test data
d. hidden data
Solution: (d)
Q30. Supervised learning and unsupervised clustering both require at least one
a. hidden attribute.
b. output attribute.
c. input attribute.
d. categorical attribute.
Solution: (b)
Q31.Supervised learning differs from unsupervised clustering in that supervised learning requires
a. at least one input attribute.
b. input attributes to be categorical.
c. at least one output attribute.
d. ouput attriubutes to be categorical.
Solution: (a)
🙏🙏Please hit the 🔔Bell icon to get the notrification from Abhinav's Blog
Abhinav's Blog
Abhinav's Blog



{kind=link}
No comments:
Post a Comment